Te-Lin Wu (吳德霖)
Member of Technical Staff, AI
Email: telinwu [at] cs (dot) ucla (dot) edu
Google Scholar / LinkedIn / Github

I am one of the early founding members in the AI domain of a stealth video AI startup.
Previously, I was a researcher at Character.ai working on large language models (LLMs) and model post-training for smarter and more amusing chatbots.
Prior to that, I obtained my PhD at UCLA PlusLab advised by Nanyun (Violet) Peng,
where my research focuses on multimodal models across NLP and computer vision.
I have also worked with Joseph J. Lim on reinforcement learning and vision for robotics topics.
Prior to PhD, I obtained my M.S. at Stanford University where I was advised by Silvio Savarese,
and I did my undergrad at National Tsing-Hua University (國立清華大學).
Over the summers, I've been lucky to work as research interns in several wonderful groups, including
Google Research, Meta Reality Labs, Amazon AI, and Adobe Research.
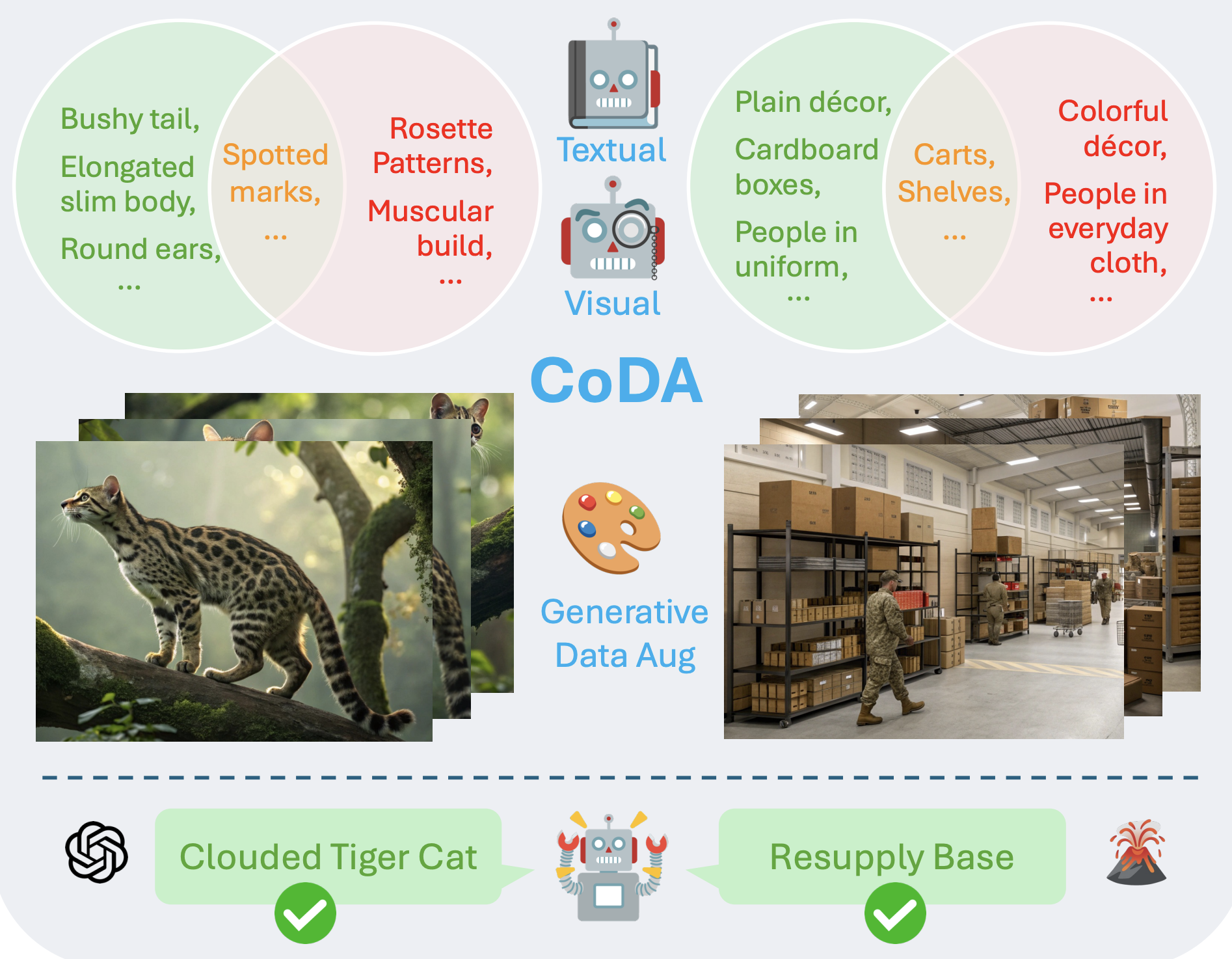
Contrastive Visual Data Augmentation
ICML 2025 /
Paper
An elegantly designed contrastive framework to improve vision-language models on learning novel concepts.

Agent-DocEdit: Language-Instructed LLM Agent for Content-Rich Document Editing
COLM 2024 /
Paper
A modularized LLM-agent approach for content-rich multimodal document editing.

DACO: Towards Application-Driven and Comprehensive Data Analysis via Code Generation
NeurIPS Datasets and Benchmarks Track 2024 /
Paper
A new dataset for complex data analysis tasks and newly proposed RLHF techniques for the tasks.

VDebugger: Harnessing Execution Feedback for Debugging Visual Programs
EMNLP 2024 (Findings) /
Paper
A debugging tool for visual program generator.

LegalDiscourse: Interpreting When Laws Apply and To Whom
NAACL 2024 /
Paper
A novel legal-related dataset that emphasizes on the discourse and the taxonomy of span-and-relation parsing.


COM2SENSE: A Commonsense Reasoning Benchmark with Complementary Sentences
A dataset for complementary commonsense reasoning collected via a model-in-the-loop gamified session.
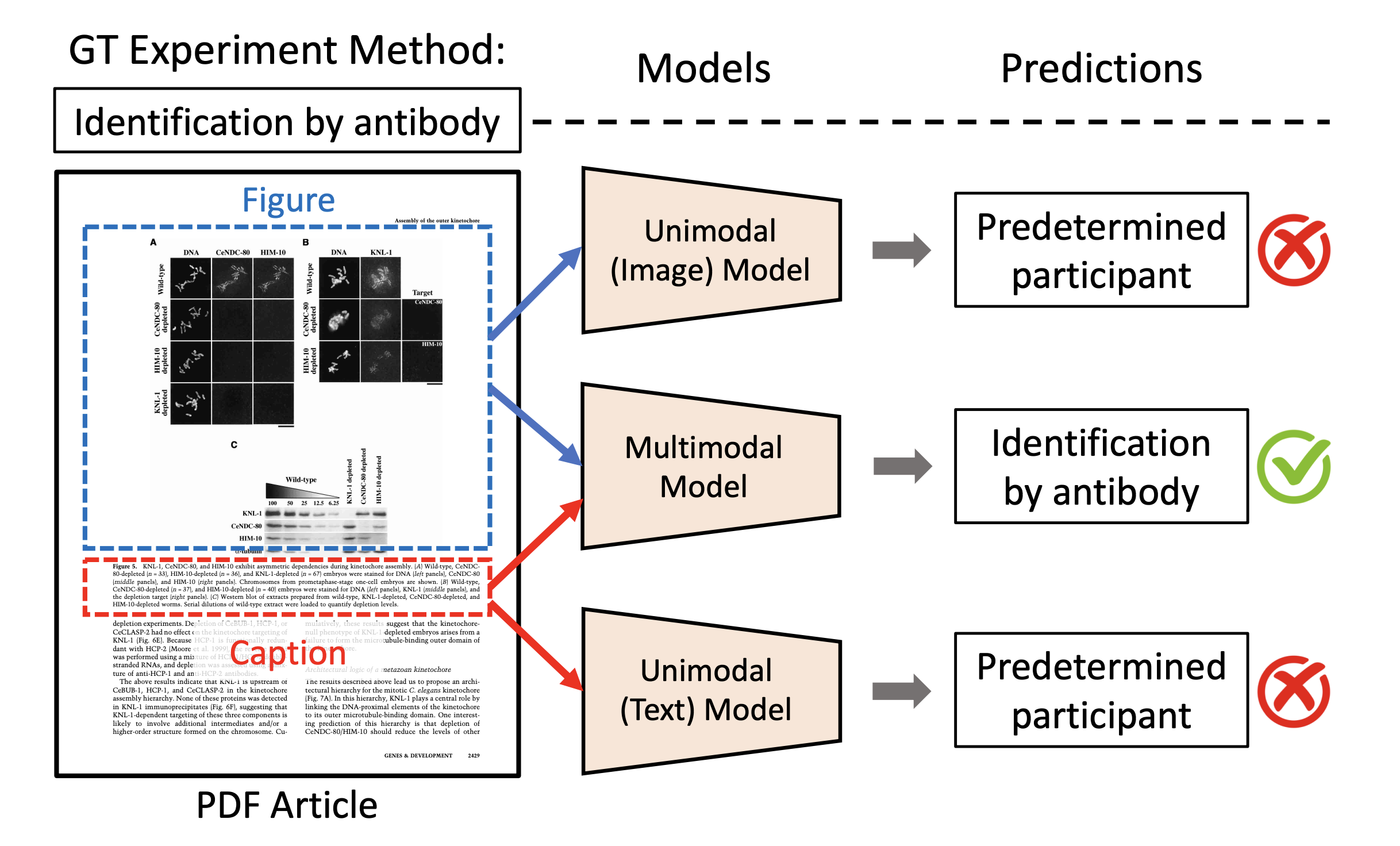
MELINDA: A Multimodal Dataset for Biomedical Experiment Method Classification
A dataset for multimodal biomedical method classification.
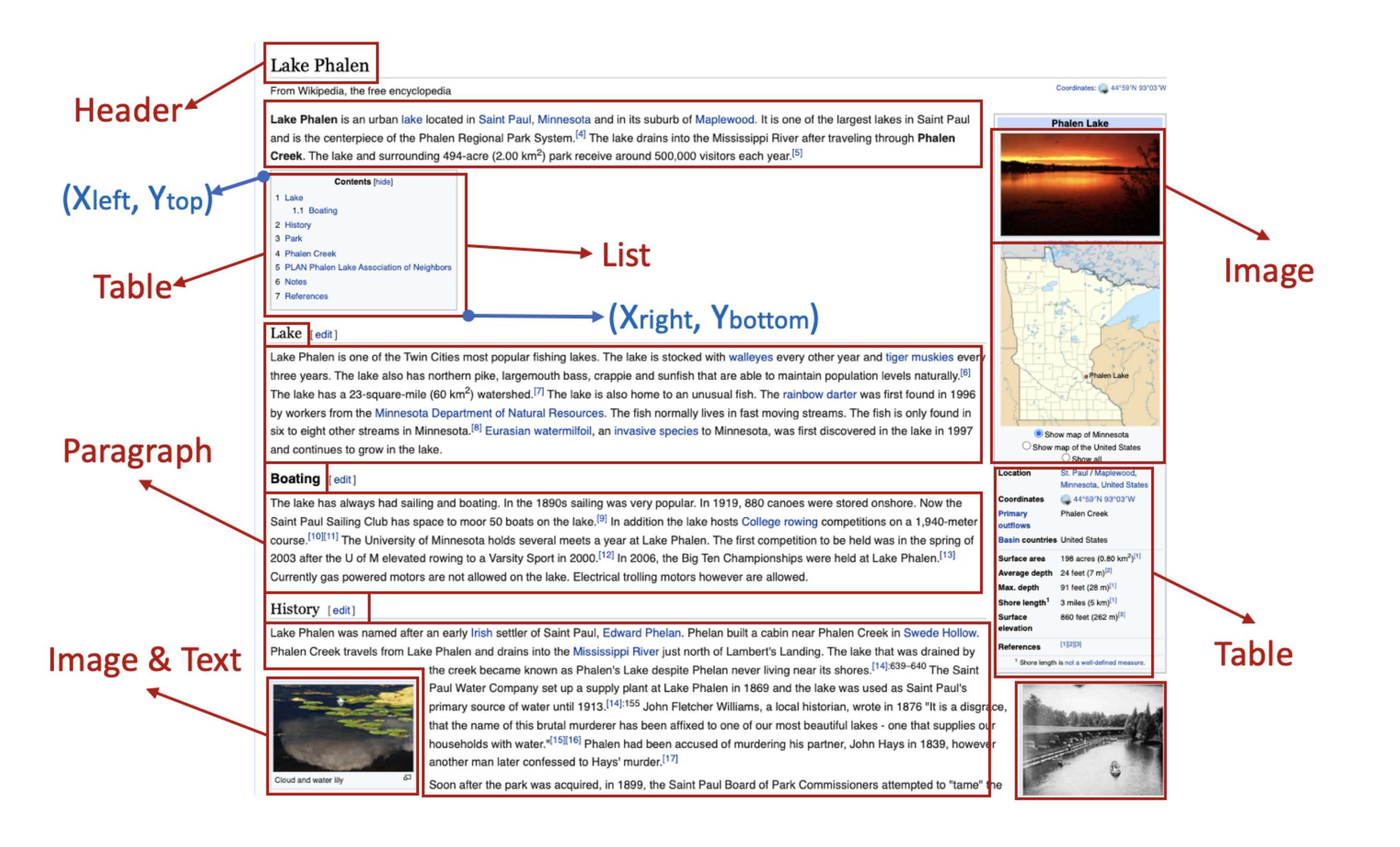
LAMPRET: Layout-Aware Multimodal PreTraining for Document Understanding
ViGIL Workshop, NAACL 2021 /
Paper
A pre-training paradigm to exploit document layout to learn a document representation.
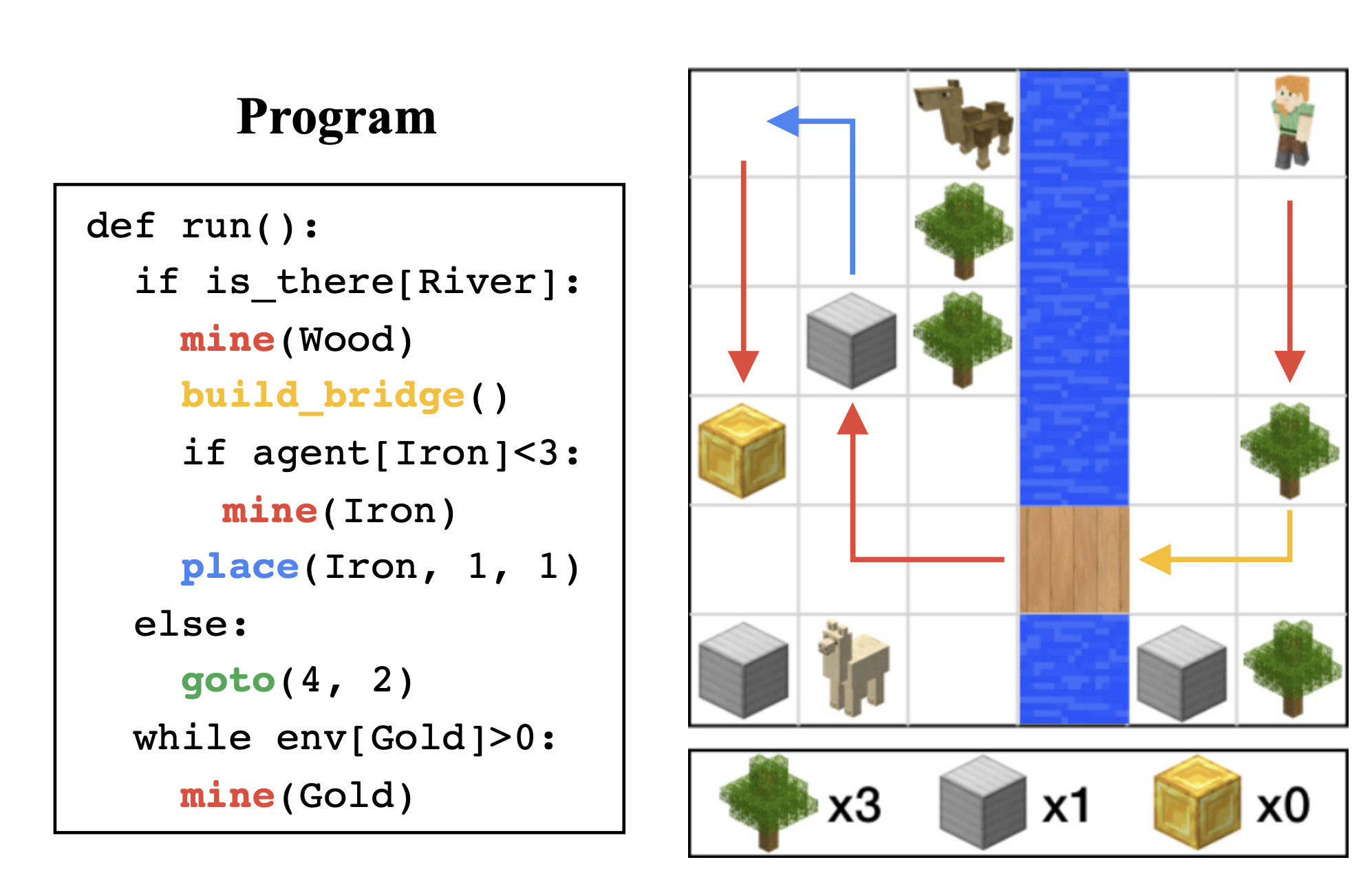
Program Guided Agent
ICLR 2020
A framework to programmatically control an RL-trained agent.
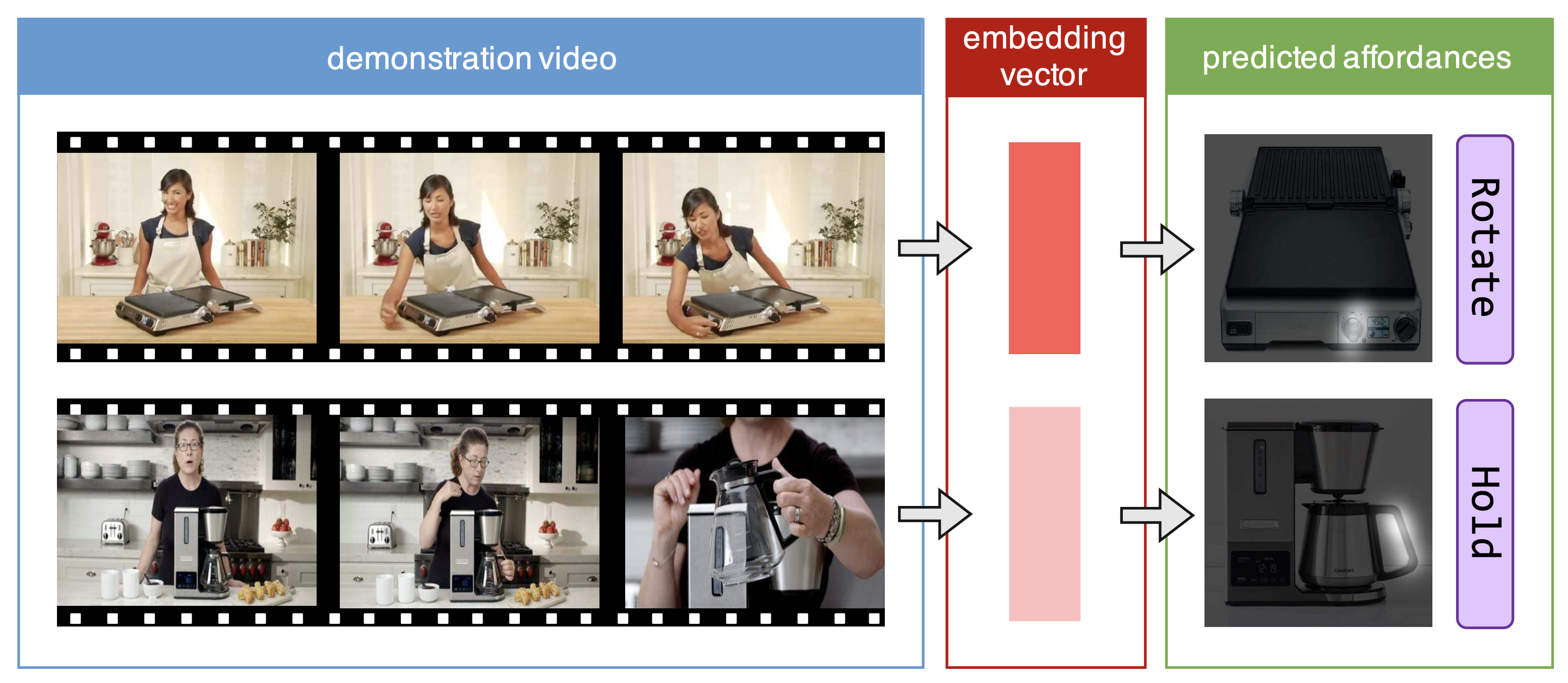
Demo2Vec: Reasoning Object Affordances from Online Videos
CVPR 2018
Learning to infer object affordance with a video demonstration of how to interact with objects.
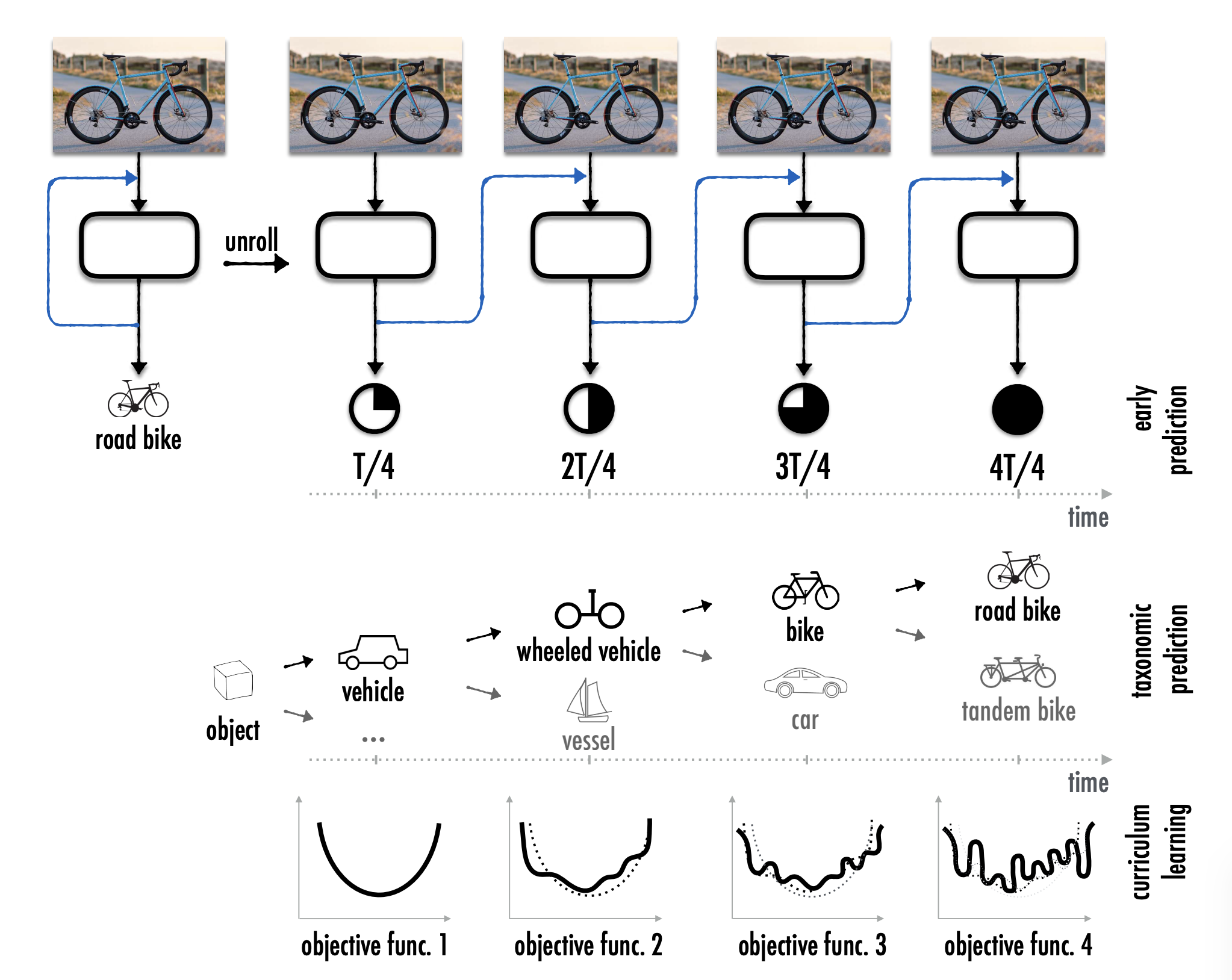
Feedback Networks
CVPR 2017
A study of feedback mechanism of convolutional neural networks.